★ NVIDIA DGX STATION は販売終了となりました ★
DGX STATION A100 ラインナップ
- 160GBモデル(NVIDIA A100 Tensor Core GPU 40GB × 4 基搭載)
- 320GBモデル(NVIDIA A100 Tensor Core GPU 80GB × 4 基搭載)
NVIDIA A100 Tensor Core GPUを搭載したモデルがリリースされました。
DGX STATION A100は、デスクサイドに設置可能なワークステーションサイズです。
静音に優れ、データ センターの電力と冷却機能を必要としない AI システム。
CPUにAMD 64Core EPYCを搭載。NVIDIA A100 GPU が 4 つ完全相互接続されています。各GPU間は200GB/Secの第三世代NVLinkで接続されており、Gen4のPCI-Expressと比較して3倍のバンド幅を実現。
DGX Station A100 は、オフィス内や研究室など、どこにでも設置でき、データセンター並みのパフォーマンスを発揮します。

DGX STATION A100 特徴
NVIDIA A100 Tensor Core GPU を搭載した初のワークステーション
- A100 Tensor Core GPU × 4 基搭載
- 最大320GBのHBM2E
- 第3世代のNVLink
- あらゆるGPU間で 200GB/秒の双方向帯域幅(PCIe Gen4の約3倍)
新しい冷却システム ポンプ冷却による2段階冷却
- メンテナンスフリーの密閉型システム(水位の確認や補充が不要)
- CPUと4基のGPUのためのシングルループ
- 無毒、不燃性、非凝縮
CPUおよびメモリ
- 64コア AMD EPYC™ CPU、PCle Gen4
- 512GB システムメモリ
内部ストレージ
- OS用 NVME M.2 SSD
- データキャッシュ用 NVME U.2 SSD
接続性
- 10GbE(RJ45)×2
- Mini DisplayPort ×1(映像出力用)
- リモート管理用 1GbE LANポート(RJ45)

職場や自宅にデータセンターのパフォーマンスをもたらします
あらゆる
ワークロードに対応
DGX Station A100 を利用すれば、組織は、NVIDIA DGX™ ベースの他のインフラストラクチャとシームレスに統合されたシステムを利用し、あらゆるワークロード (トレーニング、推論、データ分析) のために、集中型 AI リソースを複数のユーザーに提供できます。
また、マルチインスタンス GPU (MIG) を利用すると、最大 28 台の独立した GPU デバイスを個々のユーザーに割り当てることができます。
データセンターと
同等のパフォーマンス
DGX Station A100 は、サーバー級ながら、データ センターの電力と冷却機能を必要としない AI システムです。
DGX Station A100 は 4 つの NVIDIA A100 Tensor コア GPU、最上位のサーバー級 CPU、超高速 NVMe ストレージ、最先端の PCIe Gen4 バスを備えています。それに加えてリモート管理が可能で、サーバーのように管理できます。
どこにでも
配置できる
企業のオフィス、研究室、研究施設、さらには自宅で作業する今日のアジャイル データ サイエンス チームのために設計された DGX Station A100 には、複雑な設置作業も、多額の IT 投資も必要ありません。
一般的なコンセントにプラグを差し込むだけで数分後には稼働し、どこからでも作業できます。
より大規模なモデル、
より高速な応答
NVIDIA DGX Station A100 は、MIG 対応 NVIDIA A100 GPU が 4 つ完全相互接続された、世界で唯一のワークステーションスタイル システムです。NVIDIA® NVLink® によって、システム パフォーマンスに影響を与えることなく、並列ジョブを実行し、複数のユーザーに対処します。
完全に GPU 最適化されたソフトウェア スタックと最大 320 ギガバイト (GB) の GPU メモリで大規模モデルをトレーニングできます。
搭載GPU
NVIDIA A100 Tensor Core 特徴

飛躍的な世代更新 Volta の 20倍
| ピーク性能 | vs Volta | |
| FP32 学習 | 312 TFLOPS | 20倍 |
| INT8 推論 | 1,248 TOPS | 20倍 |
| FP64 HPC | 19.5 TFLOPS | 2.5倍 |

Ampere
世界最大の7nmチップ
548トランジスタ、HBM2

第3世代 Tensor Cores
更なる高速化、柔軟性、簡便
20倍のAI性能(TF32)
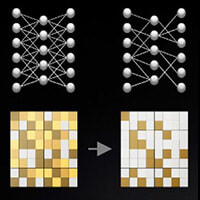
新たな高速スパース演算処理機能
AIモデルにおけるスパースを活かし
最大2倍のAI性能を発揮

新たなマルチインスタンスGPU
GPUあたり最大7つの
同時実行可能インスタンス

第3世代 NVLINK & NVSWITCH
システム性能最大化のための
効率的なスケーリング、2倍以上の帯域
新たなマルチインスタンス GPU (MIG)とは・・・
GPU を利用できるユーザーが増える
MIG を利用すれば、1 つの A100 GPU で GPU リソースを最大 7 倍にすることができます。MIG があれば、研究者や開発者はこれまでにない多くのリソースと柔軟性を得られます。
GPU 利用率を最適化する
MIG には、さまざまなインスタンス サイズを選択できる柔軟性があり、各ワークロードに適した規模で GPU をプロビジョニングできます。結果的に、利用率が最適化され、データ センターに対する投資が最大化されます。
混合ワークロードを同時実行する
MIG を使用すると、推論、トレーニング、ハイ パフォーマンス コンピューティング (HPC) といった複数のワークロードを、互いのレイテンシとスループットに影響を与えることなく単一 GPU 上で同時に実行できます

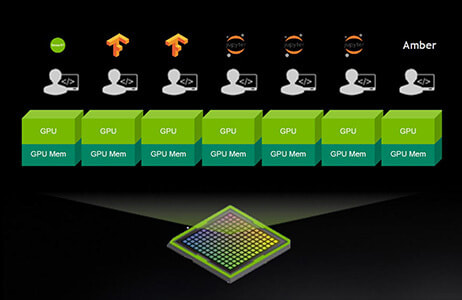
NVIDIA DGX ソフトウェアスタック
最適化されたディープラーニングフレームワークがすぐに使える
DGX システムは、DGX共通のソフトウェアスタックを備えています。
AI チューニングされた基本オペレーティング システム、必要となるすべてのシステム ソフトウェア、GPU 対応アプリケーション、トレーニング済みモデル、NGC™ の各種機能など、テスト済みで最適化された DGX ソフトウェア スタックが統合されています。
すべてのDGX システムにおいて、ソフトウェア、ツール、NVIDIA専門スタッフからなる統合的なソリューションが、すばやい利用開始、迅速なトレーニング、スムーズな運用を実現します。
NVIDIA DGX STATION A100 スペック
NVIDIA DGX STATION A100 製品カタログ
