次世代の AI を支える
NVIDIA DGX™ B200は、NVIDIA DGX プラットフォームに追加された最新モデルです。
この統合 AI プラットフォームは、NVIDIA Blackwell GPU と高速インターコネクトを最大限に活用することで生成 AI の次のステップを定義づけるものとなります。
8基のBlackwell GPUで構成された DGX B200は、膨大な 1.4 テラバイトのGPUメモリと毎秒 64テラバイト(TB/秒)のメモリ帯域幅で比類なき生成 AI パフォーマンスを実現し、あらゆる企業における AI ワークロード処理に最適です。
NVIDIA DGX B200を利用することで、企業はデータ サイエンティストや開発者に汎用的な AIスーパーコンピューターを与えることになり、洞察を得るまでの時間を短縮し、ビジネスにおける AI の利点を十分に実現することができます。
NVIDIA DGX B200 特長
強力なGPU性能
8基のNVIDIA Blackwell GPUを搭載し、合計1,440GBのGPUメモリ
高速ネットワーク
400Gb/sのネットワーク速度を実現するNVIDIA ConnectX-7ネットワークインターフェースを備え、データ転送を高速化
優れたスケーラビリティ
72ペタフロップスのトレーニング性能と144ペタフロップスの推論性能。前世代と比較してトレーニング性能は3倍、推論性能は15倍
高度なストレージ
30TBのNVMe SSDを搭載し、高速なデータアクセスを実現
高性能なCPU
デュアルIntel Xeon Platinum 8570プロセッサを搭載し、合計112コアと4TBのシステムメモリ
NVIDIA DGX B200 スペック

※ 仕様は変更になる場合があります。
| NVIDIA DGX B200 | |
| 搭載GPU | NVIDIA B200 Tensor コアGPU[180GB] × 8基 |
| GPUメモリ | 合計 1,440GB |
| 演算性能 | 72peta FLOPS トレーニング 144peta FLOPS 推論 |
| NVIDIA® NVSwitch™ | × 2 |
| CPU | Intel® Xeon® Platinum 8570 プロセッサ × 2 合計 112コア 2.1GHz(ベース)、4.0GHz(最大ブースト) |
| システムメモリ | 最大 4TB |
| ネットワーキング | 4 個のOSFP ポートで 8 個のシングルポートを提供する NVIDIA ConnectX-7 VPI >最大 400Gb/秒の InfiniBand/Ethernet 2 個のデュアルポート QSFP112 BlueField-3 DPU >最大 400Gb/秒の InfiniBand/Ethernet |
| ストレージ | OS: 2 個の 1.9TB NVMe M.2 内部ストレージ: 8 個の 3.84TB NVMe U.2 |
| システムソフトウェア | ・NVIDIA AI Enterprise – 最適化された AI ソフトウェア ・NVIDIA Base Command™ – オーケストレーション、スケジューリング、クラスター管理 ・DGX OS / Ubuntu – オペレーティング システム |
| システムサイズ | 高さ 442mm × 幅 482.6mm × 長さ 907.8mm、142.38kg |
| 運用温度範囲 | 5 - 30°C |
| 最大消費電力 | 最大 10.2kW |
| 企業向けサポート | ・ハードウェアとソフトウェアの 3 年間のエンタープライズ Business-Standard サポート ・年中無休のエンタープライズ サポート ポータル アクセス ・営業時間中のライブ エージェント サポート |
NVIDIA DGX B200 パフォーマンス
NVIDIA は、企業が直面する最も複雑な AI 問題に対処するための、世界で最もパワフルな次世代スーパーコンピューターの設計に取り組んでいます。DGX B200 はNVIDIA アクセラレーテッド コンピューティング プラットフォームの最新製品であり、その取り組みを示すものです。
革新的NVIDIA Blackwell アーキテクチャによる高度なコンピューティングの進化により、DGX B200 は DGX H100 と比較してトレーニング性能が 3 倍、推論性能が 15 倍となります。
NVIDIA DGX POD™ リファレンスアーキテクチャの基盤である DGX B200 は NVIDIA DGX BasePOD™ と NVIDIA DGX SuperPOD™ を支える優れた高速性と拡張性を提供し、手間のかからない AIインフラ ソリューションで最高レベルのパフォーマンスを実現します。
リアルタイム大規模言語モデル推論
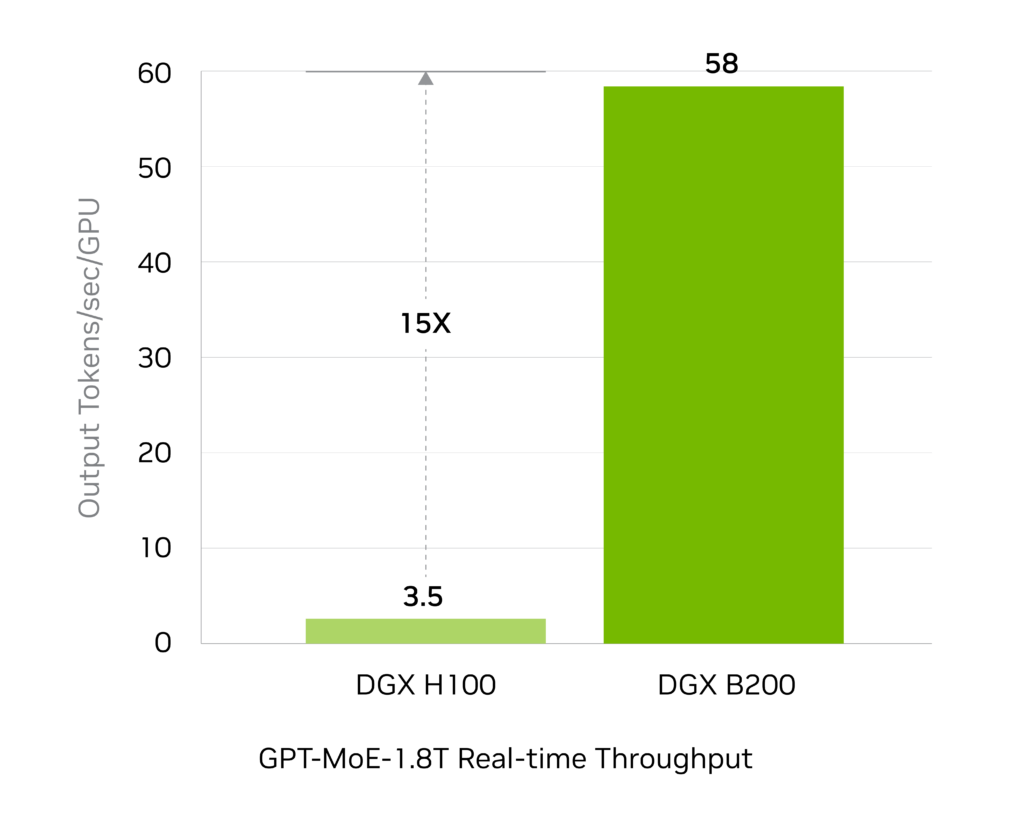
予想されるパフォーマンスは変更される可能性があります。トークン間のレイテンシ (TTL) = 50ms リアルタイム、最初のトークンのレイテンシ (FTL) = 5ms、入力シーケンスの長さ = 32,768、出力シーケンスの長さ = 1,028、8x 8ウェイ HGX H100 GPU 空冷と 1x 8ウェイ DGX B200 空冷の比較、GPU あたりのパフォーマンス比較
大幅に強化された AIトレーニング性能

予想されるパフォーマンスは変更される可能性があります。32,768 GPU スケール、4,096x 8ウェイ DGX H100 空冷クラスター: 400G IB ネットワーク、4,096x 8ウェイ DGX B200 空冷クラスター: 400G IB ネットワーク。
NVIDIA DGX プラットフォーム
実証済みインフラ標準
NVIDIA DGX B200 は、NVIDIA Blackwell GPU を搭載した世界初のシステムであり、大規模言語モデルや自然言語処理など、世界で最も複雑な AI 問題を処理するための画期的なパフォーマンスを提供します。
DGX B200 は、完全に最適化されたハードウェアおよびソフトウェア のプラットフォームです。
NVIDIA AI ソフトウェアのフル スタックを備え、多様なサードパーティのサポートを受けられる充実したエコシステムを利用でき、さらに NVIDIA プロフェッショナル サービスにより専門家からのアドバイスを受けることができます。組織は AI を利用し、最大かつ最も複雑なビジネス問題を解決できます。
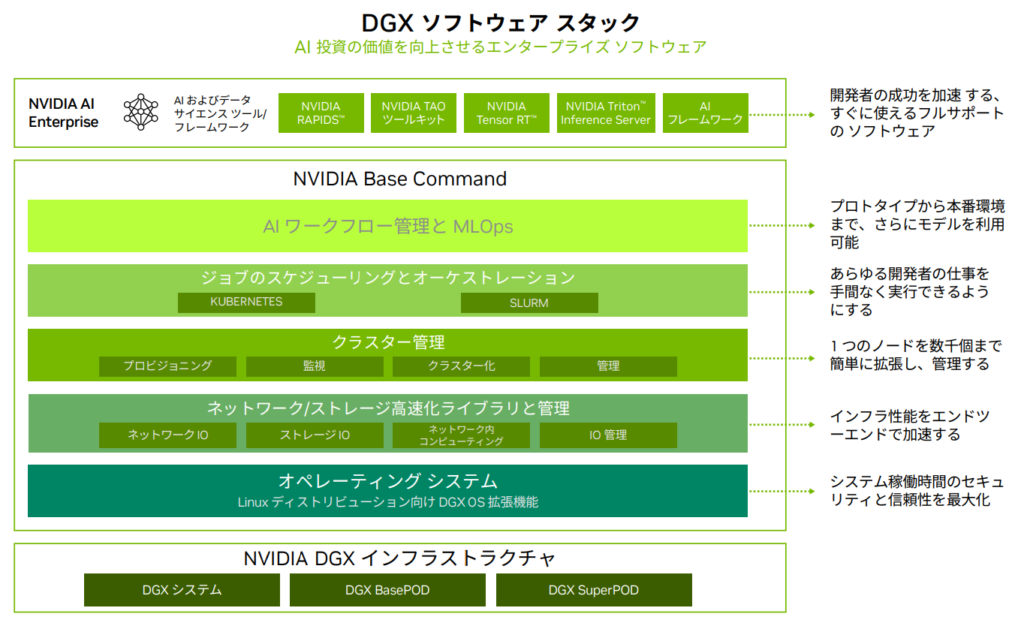
NVIDIA Base Command 搭載
NVIDIA Base Commandは DGX プラットフォームを強化し、NVIDIA ソフトウェアがもたらすイノベーションを企業が最大級活用できるようにします。
企業は、エンタープライズグレードのオーケストレーションとクラスター管理、コンピューティング、ストレージ、ネットワークのインフラを高速化するライブラリ、AI ワークロード向けに最適化されたオペレーティング システムを含む実証済みのプラットフォームで、DGX インフラの可能性を最大限まで引き出すことができます。
また、DGX インフラには、AI の開発と展開を効率化するために最適化された一連のソフトウェア、NVIDIA AI Enterprise も含まれています。
NVIDIA DGX B200 カタログ
